



Codex で Serena を使うためのセットアップ&コンテキスト削減の調査レポ
はじめに
お久しぶりです。しゅんちゃんです。寒くなってきましたね。Nextat AI活用ブログ記事シリーズとして Serena について書いてみます。
TL;DR
- Serena は LSPを使用してコードを構造的に理解し、LLM/コーディングエージェントに「ファイル全体の読み込み・grep 検索」以外の選択肢を提供する MCP サーバーです。
- 横断的なシンボル探索や依存追跡に強く、タスクによってはコンテキスト使用量の削減が見込めます。
LLMのテキスト操作の限界
LLM/コーディングエージェントは、コードを単なるテキストファイルとして扱います。結果として...
- ファイル全体を読み込んだり、grep/置換したりするため、処理時間とコンテキスト使用量が増えやすい
- 宣言と参照の関係を踏まえずに置換するので、誤編集する可能性がある
- 型やシンボルの関係が見えないため、大規模になるほどコードベースの俯瞰が難しくなる
ここを補うのが Serena の役割です。
Serenaの概要
- 何者か:IDE のようにシンボルを抽出してリレーショナルに扱える、セマンティックコード検索・編集ツールを LLM に提供するオープンソースの MCP サーバー
- 仕組み:各言語のLSP(Language Server Protocol)を使用して定義・参照・型情報などを取得して、シンボル単位の操作を可能にしている。
- 対応言語(弊社主要言語のみを抜粋)
- Go(gopls のインストールが必要)
- JavaScript / TypeScript
- Python
- PHP(LSP として Intelephense を使用している。プレミアム機能を使用するには環境変数を設定する必要がある)
- Markdown(プロジェクト設定を生成するときに明示的に
--language markdownを指定する必要がある。ドキュメントの多いプロジェクトで有効)
- 利用先:Claude Code/Desktop、Codex、Gemini-CLI、VSCode/Cursor/IntelliJ、Cline/RooCode、OpenWebUI、Jan、Agno などのクライアントから MCP として利用可能
セットアップ(Codex連携)
前提として、バージョンは下記です。- Codex:v0.57.0
- Serena:v0.1.4
- uv:v0.8.17
- uvのインストール
公式手順: https://docs.astral.sh/uv/getting-started/installation/ - Codex の MCP 設定(
~/.codex/config.toml)[mcp_servers.serena] command = "uvx" args = ["--from", "git+https://github.com/oraios/serena", "serena", "start-mcp-server", "--context", "codex"] startup_timeout_sec = 30起動に時間がかかり、
MCP client for `serena` failed to start: request timed outとなることがあるため、タイムアウト時間(startup_timeout_sec)を設定しています。 - ダッシュボード制御
Codexを起動したら、ダッシュボードがhttp://localhost:24282/dashboard/index.htmlで起動します。
毎回は不要なら Serena のグローバル設定(~/.serena/serena_config.yml)で無効化できます。web_dashboard_open_on_launch: false
使い始め(activate/onboarding)
- プロジェクトのアクティブ化
プロンプト例:Serenaを使用して現在のディレクトリをプロジェクトとしてアクティブ化してCodex から Serena のツール
activate_projectが呼ばれ、プロジェクトがアクティブ化されます。 - オンボーディング
下記のプロンプトでonboardingを実行できます。Serenaを使用して現在のプロジェクトでオンボーディングを開始して.serena/memories/にプロジェクトの概要・コーディングスタイル・コマンド集・タスク完了条件などが Markdown として保存されます。 以後、Serena はこれらのメモリファイルを参照し、Codex やその他の LLM/コーディングエージェントはプロジェクトに沿った提案をしやすくなります。
Serena を使用した場合にコンテキストウィンドウの使用量は削減できるか
同一タスクを Serena あり/なしで比較し、Codex のコンテキストウィンドウの使用量を簡易比較します。
用意したプロンプト(task.md)
Codex にプロジェクトのテストコードに対するリファクタリング案を提案してもらおうと思います。
## GOAL
- 既存のテストコードのリファクタリング案を出力する
## 入力
- `./tests`以下のテストコード
## 出力
- `./調査`以下にMarkdownファイルとして結果を出力すること
Serena を使用した場合
Codex への指示:
Serenaを使用してtask.mdを実行して
Codex が生成した計画:
• Updated Plan
└ □ tests 以下の構成を把握し、主要テスト群を選定する
□ 代表的なテストコードをSerenaで確認しリファクタリング案を洗い出す
□ 調査結果を調査配下のMarkdownに整理する
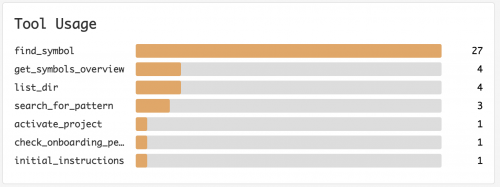
Serena のツール(find_symbol, get_symbols_overview, search_for_pattern など)を使って探索が行われました。
ダッシュボードでツールの使用回数のグラフをみることができます。
作業完了後、/status の結果:
Context window: 78% left (68.7K used / 272K)
コンテキストウィンドウを 約22% 使用していました。
Serena を使用しない場合
Codex への指示:
Serenaを絶対に使用せずtask.mdを実行して
Codex はListやReadなどCodex の標準ツールを使用して、コードベースの探索を行いました。
/status の結果:
Context window: 66% left (99.3K used / 272K)
コンテキストウィンドウを 約34% 使用しており、Serena を使用した時と比較して、約11% 多く使用していることがわかります。
まとめ
Codex と Serena の連携方法、およびコンテキストウィンドウ使用量を比較しました。 単一タスクの比較では、Serena を使用した方がやや効率的である可能性が見られました。今回は編集系ツール(insert_after_symbol など)を使っていないため、編集タスクを含めるとさらに差が広がる可能性があります。


![[difit] AIが書いたコードをGitHubのPull Request風の画面でレビューし、AIに修正させる](/files/uploads/difit_sample_1.png)